Load the libraries and avoid conflicts, and prepare data
# Load libraries used everywherelibrary(tidyverse)library(tidymodels)library(tidyclust)library(purrr)library(ggdendro)library(fpc)library(mclust)library(kohonen)library(patchwork)library(mulgar)library(tourr)library(geozoo)library(ggbeeswarm)library(colorspace)library(detourr)library(crosstalk)library(plotly)library(ggthemes)library(conflicted)conflicts_prefer(dplyr::filter)conflicts_prefer(dplyr::select)conflicts_prefer(dplyr::slice)conflicts_prefer(purrr::map)
🎯 Objectives
The goal for this week is practice fitting model-based clustering and self-organising maps.
🔧 Preparation
Make sure you have all the necessary libraries installed.
Exercises:
1. Clustering spotify data with model-based
This exercise is motivated by this blog post on using \(k\)-means to identify anomalies.
You can read and pre-process the data with this code. Variables mode, time_signature and instrumentalness are removed because they have just a few values. We have also transformed some variables to remove skewness, and standardised the data.
Fit model-based clustering with number of clusters ranging from 1-15, to the transformed data, and all possible parametrisations. Summarise the best models, and plot the BIC values for the models. You can also simplify the plot, and show just the 10 best models.
The best parametrisation is the VVE model, and four clusters yields the best BIC.
Why are some variance-covariance parametrisations fitted to less than 15 clusters?
Solution
The number of parameters needed is too many for the number of observations.
Make a 2D sketch that would illustrate what the best variance-covariance parametrisation looks like conceptually for cluster shapes.
How many parameters need to be estimated for the VVE model with 7 and 8 clusters? Compare this to the number of observations, and explain why the model is not estimated for 8 clusters.
Solution
VVE means the volume and shape are variable, and a common orientation between clusters. It can be written as \(\lambda_k D A_k D^\top\).
\(D\) (one \(11\times 11\)-D matrix, upper and lower triangles the same): \(\sum_{i=1}^8 i = 36\)
\(\lambda_k\) (8 size parameters): 8
\(\pi\) (mixing proportions): \(8-1 = 7\)
For 8 clusters 227 parameters are used.
Both of these are less than the number of observations (507), so it should be possible to fit both. For 8 clusters, though it is about 2 observations per parameter. It’s not much better for 7 clusters, but the model is fitted anyway. It’s not clear why but its interesting.
Fit just the best model, and extract the parameter estimates. Write a few sentences describing what can be learned about the way the clusters subset the data.
Because the the data is standardised differences between means and variances from one cluster to another can be compared directly.
We could say that cluster 1 has high speechiness, and low energy, loudness. In contrast, cluster 4 has high energy and loudness, but low acousticness.
On the variances, cluster 1 has low variance for acousticness, which means all songs in this cluster have similar acousticness. Cluster 4 has small variance on energy and loudness, so these songs have similar values on these variables.
2. Clustering simulated data with known cluster structure
In tutorial of week 10 you clustered c1 from the mulgar package, after also examining this data using the tour in week 3. We know that there are 6 clusters, but with different sizess. For a model-based clustering, what would you expect is the best variance-covariance parametrisation, based on what you know about the data thus far?
Solution
We would expect 6 clusters would give the best results. The two big clusters are elliptical but oriented along variable axes, and have no variance in some variables. The four small clusters are spherical in the full 6D.
Fit a range of models for a choice of clusters that you believe will cover the range needed to select the best model for this data. Make your plot of the BIC values, and summarise what you learn. Be sure to explain whether this matches what you expected or not.
The music data was collected by extracting the first 40 seconds of each track from CDs using the music editing software Amadeus II, saved as a WAV file and analysed using the R package tuneR. Only a subset of the data is provided, with details:
lvar, lave, lmax: average, variance, maximum of the frequencies of the left channel
lfener: an indicator of the amplitude or loudness of the sound
lfreq: median of the location of the 15 highest peak in the periodogram
You can read the data into R using:
music <-read_csv("http://ggobi.org/book/data/music-sub.csv") |>rename(title =`...1`)
How many observations in the data? Explain how this should determine the maximum grid size for an SOM.
Solution
There are only 62 observations. If you use a 5x5 grid, this is less than 3 observations per cluster. You need to be careful about specifying a model with too many nodes for the number of observations. At the same time and SOM needs to have some flexibility to fit the data shape, and more nodes allows more flexibility.
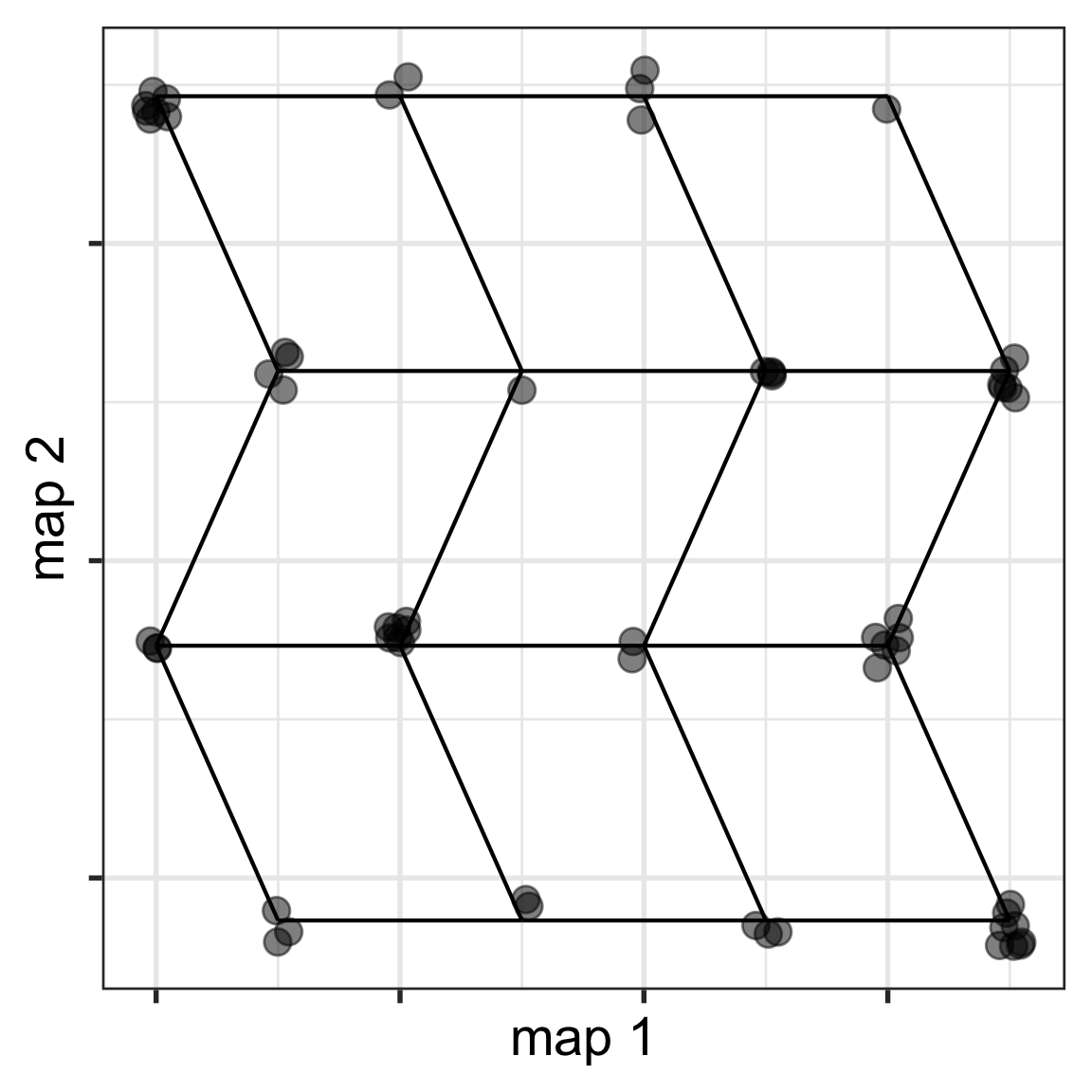
Fit a SOM model to the data using a 4x4 grid, using a large rlen value. Be sure to standardise your data prior to fitting the model. Make a map of the results, and show the map in both 2D and 5D (using a tour).