Load the libraries and avoid conflicts, and prepare data
# Load libraries used everywherelibrary(tidyverse)library(tidymodels)library(tidyclust)library(purrr)library(ggdendro)library(fpc)library(patchwork)library(mulgar)library(tourr)library(geozoo)library(ggbeeswarm)library(colorspace)library(plotly)library(ggthemes)library(conflicted)conflicts_prefer(dplyr::filter)conflicts_prefer(dplyr::select)conflicts_prefer(dplyr::slice)conflicts_prefer(purrr::map)
🎯 Objectives
The goal for this week is learn to about clustering data using \(k\)-means and hierarchical algorithms.
🔧 Preparation
Make sure you have all the necessary libraries installed.
Exercises:
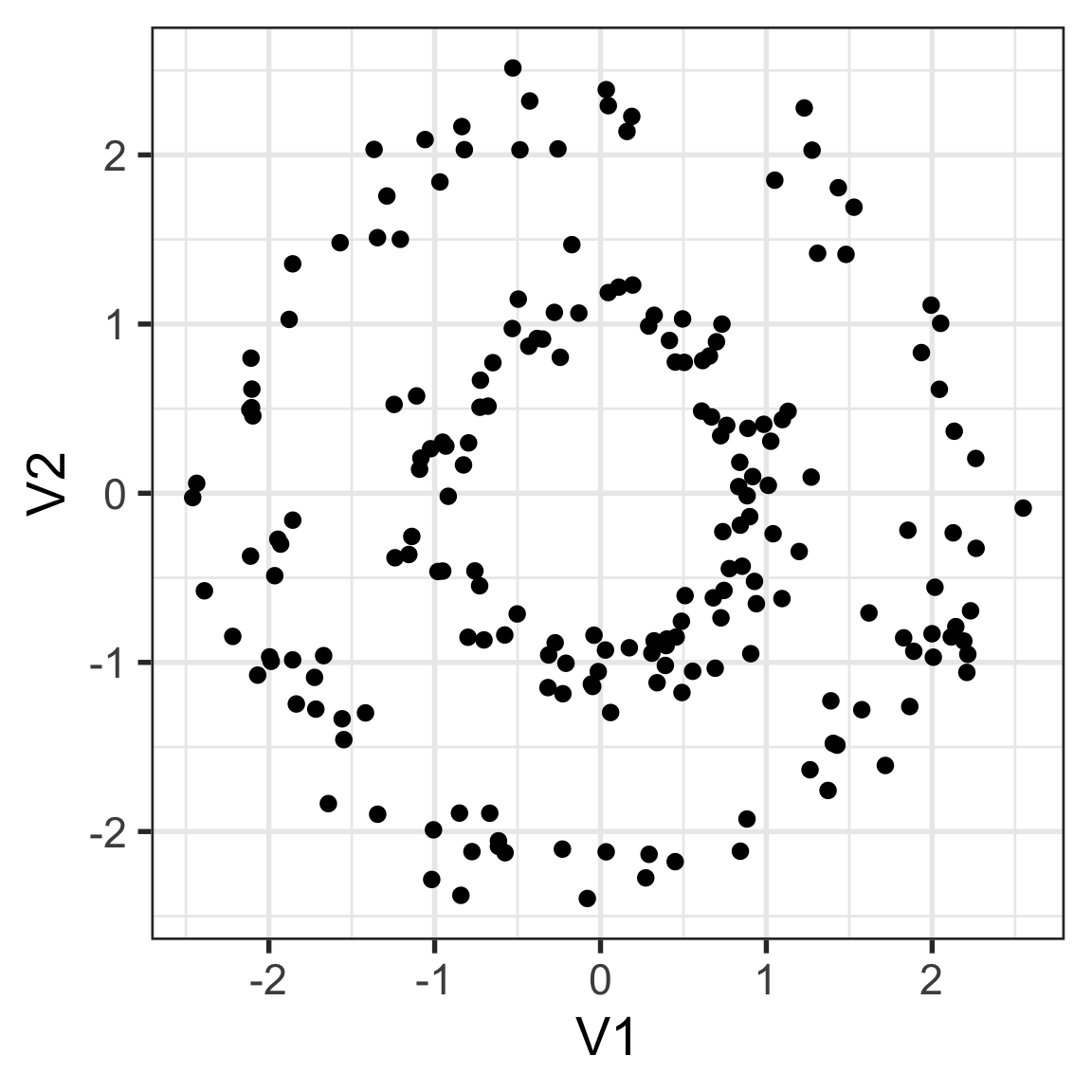
1. How would you cluster this data?
How would you cluster this data?
Derive a distance metric that will capture your clusters. Provide some evidence that it satisfies the four distance rules.
Compute your rule on the data, and establish that it does indeed capture your clusters.
2. Clustering spotify data with k-means
This exercise is motivated by this blog post on using \(k\)-means to identify anomalies.
You can read the data with this code. And because for clustering you need to first standardise the data the code will also do this. Variables mode and time_signature are removed because they have just a few values.
# https://towardsdatascience.com/unsupervised-anomaly-detection-on-spotify-data-k-means-vs-local-outlier-factor-f96ae783d7a7spotify <-read_csv("https://raw.githubusercontent.com/isaacarroyov/spotify_anomalies_kmeans-lof/main/data/songs_atributtes_my_top_100_2016-2021.csv")spotify_std <- spotify |>mutate_if(is.numeric, function(x) (x-mean(x))/sd(x)) |>select(-c(mode, time_signature)) # variables with few values
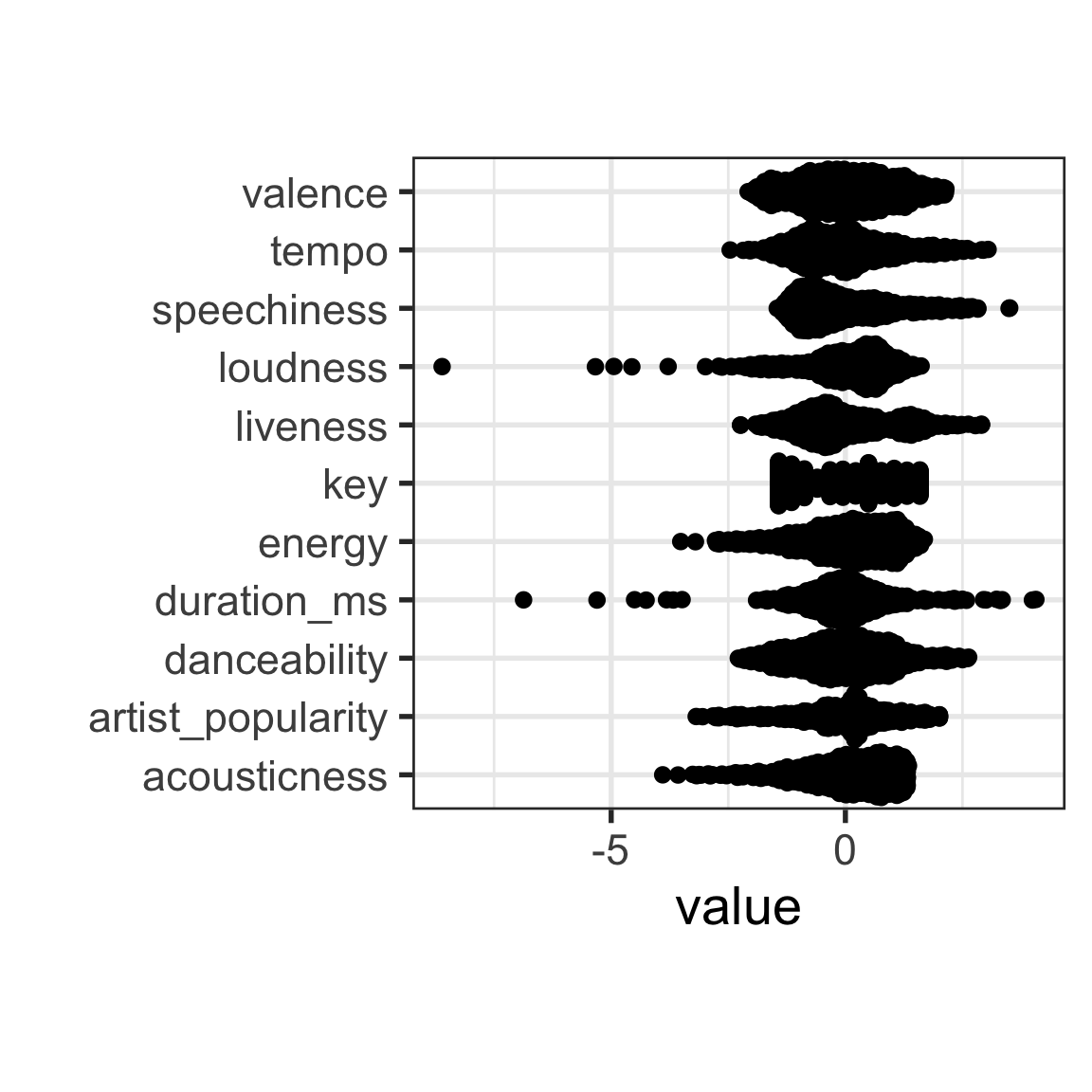
Make a plot of all of the variables. This could be a density or a jittered dotplot (beeswarm::quasirandom). Many of the variables have skewed distributions. For cluster analysis, why might this be a problem? From the blog post, are any of the anomalies reported ones that can be seen as outliers in a single skewed variable?
Transform the skewed variables to be as symmetric as possible, and then fit a \(k=3\)-means clustering. Extract and report these metrics: totss, tot.withinss, betweenss. What is the ratio of within to between SS?
Now the algorithm \(k=1, ..., 20\). Extract the metrics, and plot the ratio of within SS to between SS against \(k\). What would be suggested as the best model?
Divide the data into 11 clusters, and examine the number of songs in each. Using plotly, mouse over the resulting plot and explore songs belonging to a cluster. (I don’t know much about these songs, but if you are a music fan maybe discussing with other class members and your tutor about the groupings, like which ones are grouped in clusters with high liveness, high tempo or danceability could be fun.)
3. Clustering several simulated data sets with known cluster structure
In tutorial of week 3 you used the tour to visualise the data sets c1 and c3 provided with the mulgar package. Review what you said about the structure in these data sets, and write down your expectations for how a cluster analysis would divide the data.
Compute \(k\)-means and hierarchical clustering on these two data sets, without standardising them. Use a variety of \(k\), linkage methods and check the resulting clusters using the cluster metrics. What method produces the best result, relative to what you said in a. (NOTE: Although we said that we should always standardise variables before doing clustering, you should not do this for c3. Why?)
There are five other data sets in the mulgar package. Choose one or two or more to examine how they would be clustered. (I particularly would like to see how c4 is clustered.)
👋 Finishing up
Make sure you say thanks and good-bye to your tutor. This is a time to also report what you enjoyed and what you found difficult.